
Beyond Accuracy: Building Cost-Conscious AI Benchmarks
What happens when AI coding tests include a price tag

On most coding benchmarks you’ll see today, the leaders are the usual suspects: Claude 4 Opus, Gemini 2.5 Pro, Grok 4. These models dominate HumanEval, SWE-bench, and every other headline leaderboard.
In my experiment, they landed closer to the bottom.
Thanks for reading! Subscribe for free to receive new posts and support my work.
When you give every model a fixed budget of tokens—say, five dollars to spend however they like—the leaderboard turns upside down. Suddenly, lightweight open-source models like GPT-OSS-20B or fast specialists like Grok-Code-Fast emerge as champions. The “big names” struggle not because they can’t solve the problems, but because they waste far more compute getting there.

Pass @ Budget
Here’s the setup:
I ran HumanEval, a standard coding test set.
Instead of giving models infinite retries, I gave each a strict $5 allowance.
They could loop through problems as many times as they needed until solved, but once the budget ran out, they were done.
This reframes the question. Traditional benchmarks ask “who reaches 100% eventually?” Pass @ Budget asks “who reaches milestones cheapest?”
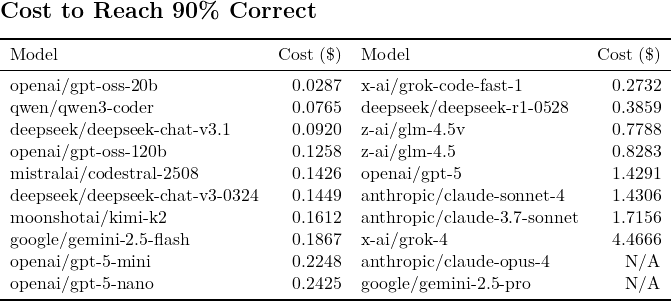
One of the cleanest ways to compare models is cost to hit 90% correctness. At that point, most of the “easy” problems are solved, and you start to see real differences in efficiency.
The leaders are not Claude 4 Opus or Gemini 2.5 Pro. They’re the cheaper, smaller, sometimes open-source models that get most of the work done for pennies.
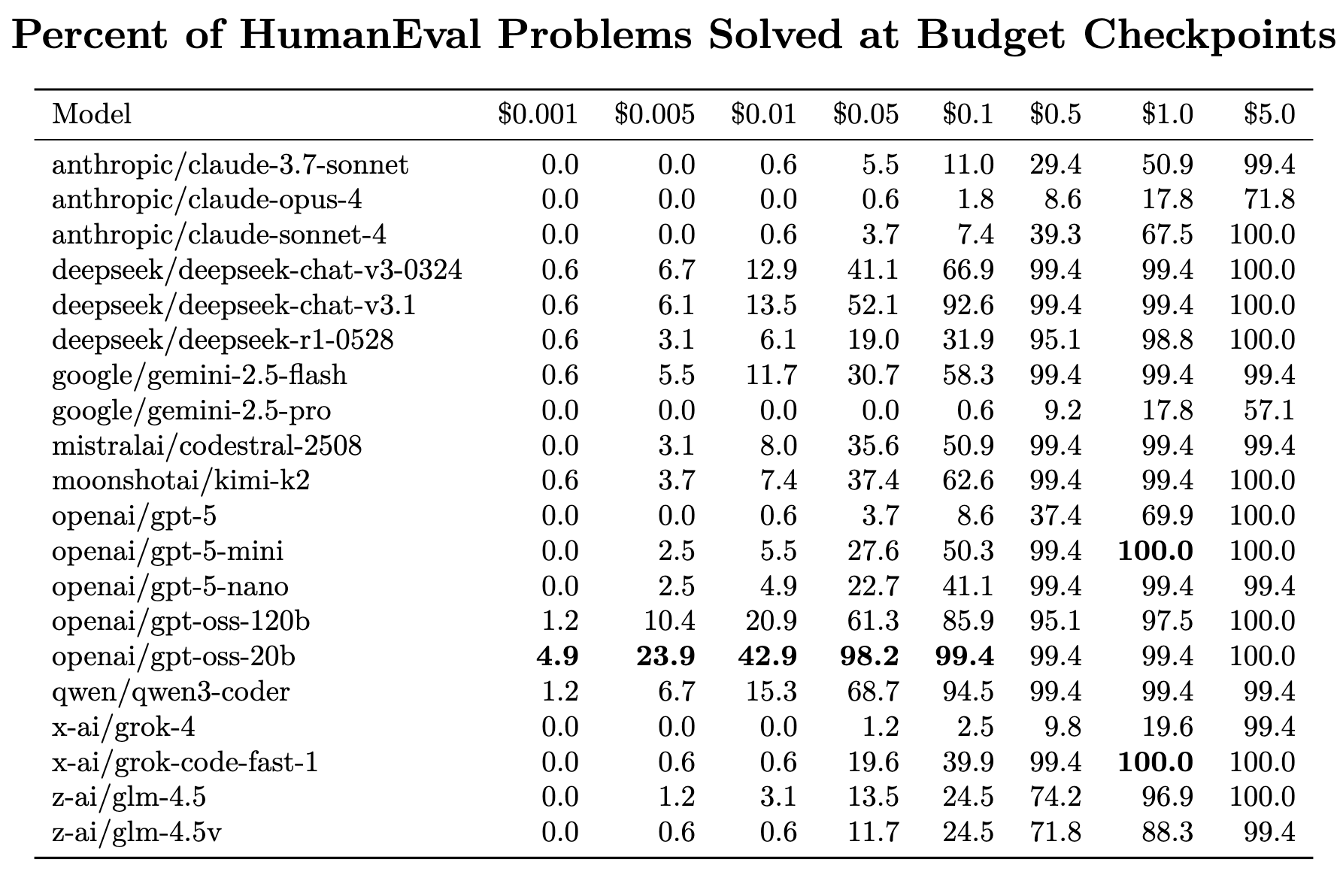
Another way to look at it is by spend checkpoints. At $0.01, $0.05, $0.10, $0.50, $1, and $5, how many problems does each model solve?
The shape is clear:
Cheap models like GPT-OSS-20B, DeepSeek v3.1, and Qwen3-Coder rack up correct answers early.
Big models like Opus and Gemini Pro never really catch up after burning through serious cost.
Last-mile efficiency varies wildly: some models need just a few extra cents to go from 99% → 100%, while others blow through dollars.
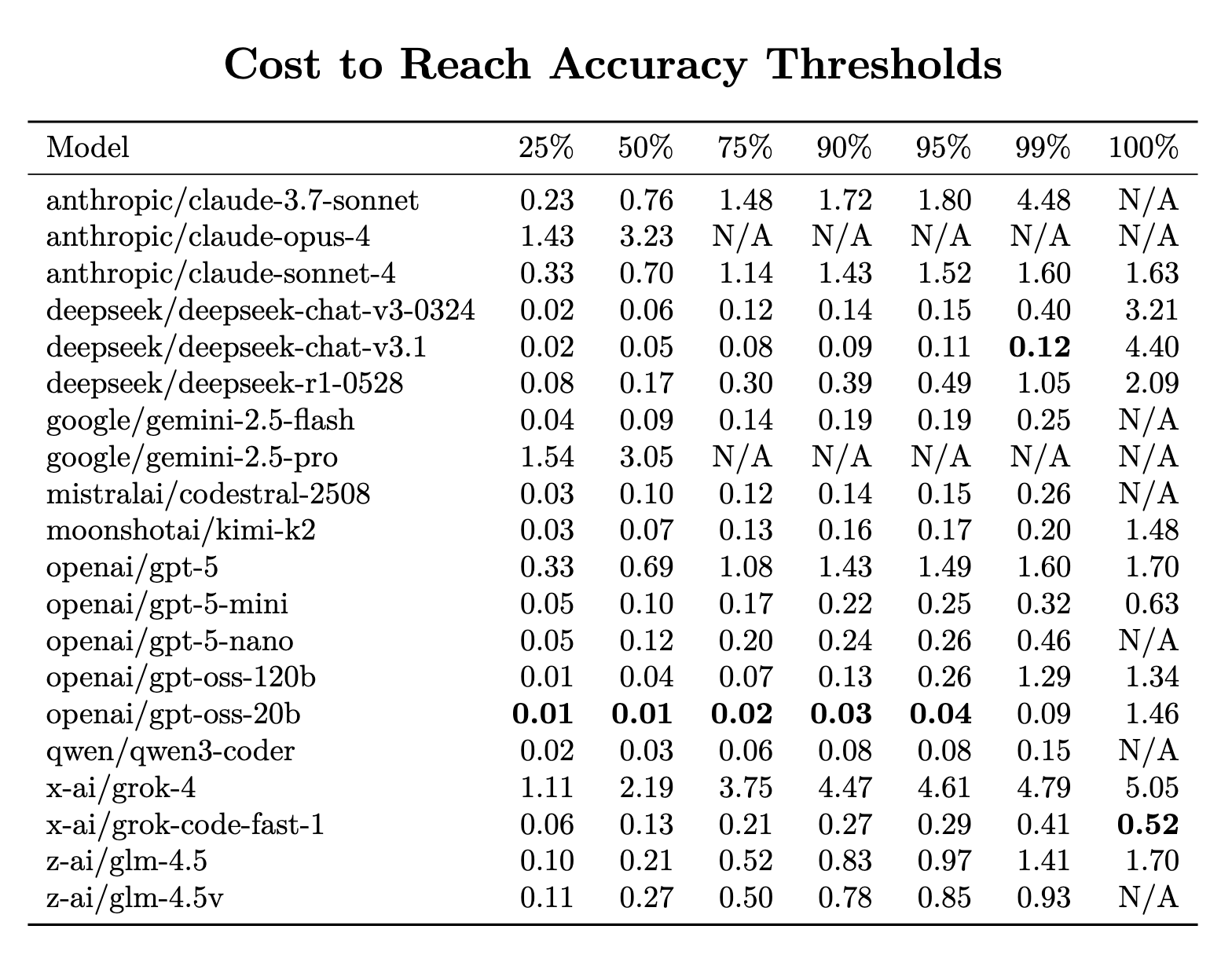
Breaking it down by thresholds paints the same picture:
25% / 50% / 75%: many models nearly free
90%: efficiency starts to matter—cheap models shine
99%: the field begins to separate
100%: chaos. Some models need pennies, others need $4+
Note - part of this is due to issues with the HumanEval benchmark
This is where the traditional leaderboard breaks down. It rewards brute-force spending to grind out the last couple of problems. Pass@Budget makes the trade-offs visible.
A New Hill to Climb
If the old goal was “reach 100%,” the new goal should be “reach it fast and cheap.”
The leaders here are not the usual frontier labs, but a surprising mix of Chinese open-source models (DeepSeek, Qwen) and specialists like Grok-Code-Fast. These systems prove that efficiency can beat scale—at least on this benchmark.
And if you zoom out, this shift echoes bigger industry stories:
Anthropic’s Dario Amodei has argued that only compute holds us back—but here’s evidence that strategy beats raw scale.
OpenAI’s new GPT-5 router tries to send you to cheaper models unless you really need heavy compute. Pass@Budget is the same idea, made measurable.
Companies like Blitzy are breaking records by scaling compute to extreme levels. But Pass@Budget asks the real question: was it worth the spend?
Thanks for reading Cool Things in AI! Subscribe for free to receive new posts and support my work.